For some projects and frameworks, working with several databases is essential. The purpose of synchronization is to ensure that these databases are available at all times. Overall, synchronization is the process of adding new records, updating old ones, and removing obsolete data.
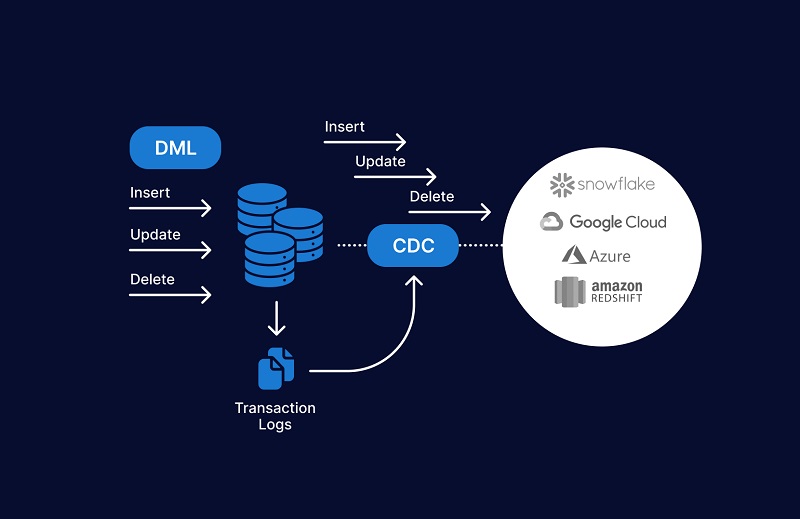
In a distributed heterogeneous database system, Incremental Database synchronization makes it possible to reflect changes made in one database to another database using pre-built triggers. Information may be recreated in near real-time by capturing and sending changes to data as they occur and providing continual synchronization across varying environments.
How does it work
The accompanying strategy is necessary for the success of incremental synchronization. If you run a synchronization between two databases for the first time, the program will:
- Fully synchronize all tables between the source and target databases (including adding any missing columns from the source, refreshing any existing lines, and removing any rows from the target that aren’t present in the source),
- Create all necessary administrative objects for incremental synchronization on subsequent runs (table to store changes and triggers on embed, refresh, and erase for each table being synchronized)
- The software constructs just the information being modified in each table when it runs synchronization again, using the incremental synchronization approach set in advance.
Advantages of the incremental sync over the classic process:
Ideal for massive data sets. Finish sync is not required on a database larger than 2 GB. Databases that have been brought up to date will show the most recent significant updates.
Increased synchronization rate. Synchronizers compile updated records and reconstruct databases with lightning speed all because of custom-built triggers.
Let’s use the following scenario to demonstrate why incremental synchronization is beneficial. Let’s pretend that there’s a database with a table containing 1,000,000 rows, and that only 1,000 entries in that table have been modified since the previous synchronization. It takes roughly 2.5 hours to synchronize the database using the traditional method (Insert/Update/Drop operations). By synchronizing in small increments, the identical process may be completed in as little as one to two minutes.
Based on the evidence provided, it is clear that our Intelligent Converters software’s trigger-based sync function is a big improvement.
Synchronization within a very short time frame of real time. The sync architecture is built on triggers, so you may execute sync sessions whenever you need to. When the books were balanced If you conduct a sync session fast (or through the Scheduler), the foreign data will reliably “win” over the data in the existing record. Therefore, your newly formed databases will always reflect the most recent developments.
Setup is a breeze. Trigger-based synchronization may be set up without the need for any advanced design skills.
For both unidirectional and bidirectional synchronizations, the trigger-based instrument of incremental synchronization is suitable.
Requirements:
- A synchronized database with trigger and table creation features is required.
- Primary Key tables are the only ones where trigger-based synchronization may be used.
See incremental synchronization in action on live data by trying out the SQL Server – MySQL Sync tool.